Discretization theory: ZOH, bilinear, exponential families
One-step discretizations of linear ODEs — zero-order hold, bilinear (Tustin), and exponential-trapezoidal — with the Lax equivalence theorem as the unifying convergence criterion.
On this page
- 4.1 The discretization problem
- 4.2 The Lax equivalence theorem
- 4.3 Zero-order hold (ZOH)
- 4.4 The bilinear (Tustin) transform
- 4.5 Exponential-family discretizations
- 4.6 Order of accuracy and the discretization hierarchy
- 4.7 What’s next
- 4.8 Exercises
- Exercise 4.1 (computation)
- Exercise 4.2 (computation)
- Exercise 4.3 (computation + code)
- Exercise 4.4 (theory) — solution in §4.9
- Exercise 4.5 (theory) — solution in §4.9
- Exercise 4.6 (theory) — solution in §4.9
- 4.9 Full solutions to theory exercises
- Solution to Exercise 4.4
- Solution to Exercise 4.5
- Solution to Exercise 4.6
- 4.10 Companion code
Discretization theory: ZOH, bilinear, exponential families
4.1 The discretization problem
Chapter 1 wrote the linear state-space system as a continuous-time ODE
defined for every . Computers do not handle “every ”; they handle a finite grid for with step size . A discretization is a rule for building a recurrence
whose iterates approximate the continuous trajectory at the grid points, . The two discrete matrices are functions of the continuous matrices and of the step size . Different functions give different discretizations.
There is no single canonical choice. Every discrete recurrence in this book — the S4 layer, the Mamba selective scan, the exp-trapezoidal scheme of Mamba-3 Lahoti et al. (2026) — picks a specific rule for translating . The choice matters: a poor discretization can take a perfectly stable continuous system and produce a discrete recurrence that diverges, fails to converge as , or accumulates phase error on long horizons. Numerical-analysis textbooks Hairer et al. (1993) spend hundreds of pages on these failure modes. We will compress them into three properties and three schemes.
A useful warm-up is forward Euler, the simplest possible scheme:
This is what you get by replacing with the forward difference and freezing the input at . The discrete matrices are and . Forward Euler is the cleanest illustration of what can go wrong: it is only conditionally stable, meaning that for any fixed with there is a maximum step size beyond which acquires an eigenvalue of modulus and the recurrence blows up. The three schemes in §4.3–§4.5 fix this defect — each in its own way, with its own trade-off.
4.2 The Lax equivalence theorem
To compare schemes you need a definition of “correct.” The standard one comes from the Lax equivalence theorem Lax & Richtmyer (1956) , which decomposes correctness into two ingredients: consistency and stability.
A one-step scheme is consistent with the ODE if its local truncation error — the residual you obtain by plugging the exact continuous trajectory into the discrete recurrence — vanishes faster than as . Formally,
If the scheme is -th order consistent. Higher means the per-step error shrinks faster with .
A scheme is zero-stable if small perturbations injected at one step propagate boundedly to all future steps. For linear schemes this reduces to a uniform bound on the powers of : there exists independent of such that for all with , for any fixed horizon . Equivalently, the spectral radius .
The two ingredients combine.
(Lax equivalence.) For a linear, well-posed initial-value problem, a one-step scheme is convergent — meaning as — if and only if it is both consistent and zero-stable.
Convergence is what you actually want: that the discrete iterates approach the true continuous trajectory as you refine the grid. The theorem says you cannot get there by being consistent alone (you also need stability) or by being stable alone (you also need consistency). Both are necessary, and together they are sufficient. This is the convergence criterion every scheme in this chapter must pass.
For a stable LTI test problem — meaning has all eigenvalues in the open left half-plane — there is a stronger notion sitting on top of zero-stability: a scheme is A-stable if for every step size , not just for sufficiently small . Forward Euler is not A-stable; ZOH, bilinear, and exp-trapezoidal are. The geometry of A-stability — the set of values for which the scheme behaves well — is the subject of Chapter 5.
4.3 Zero-order hold (ZOH)
The first scheme assumes the input is piecewise constant between samples: for . Under that assumption the inhomogeneous ODE solves exactly on a single interval. Starting from ,
Identifying the two matrices,
This is the zero-order hold (ZOH) discretization. The hold refers to the input assumption; “zero-order” refers to the polynomial degree of the held signal (a constant is a zero-degree polynomial).
A practical wrinkle: writing as requires to be invertible. The HiPPO matrix of Chapter 7 is invertible; some structured in later chapters are not. The augmented matrix exponential trick Van Loan (1978) handles both cases uniformly. Build the block matrix
where is the input dimension ( in Chapter 1’s notation). Then
and a single expm call extracts both (top-left block) and (top-right block) without ever inverting . The block identity goes back to Van Loan Van Loan (1978)
; the JAX companion discretization_comparison.py uses it.
(ZOH preserves Lyapunov stability.) If every eigenvalue of has and , then every eigenvalue of satisfies . ZOH is therefore A-stable.
The proof is one line: when and . Stability is preserved for every positive step size, which is what A-stability means.
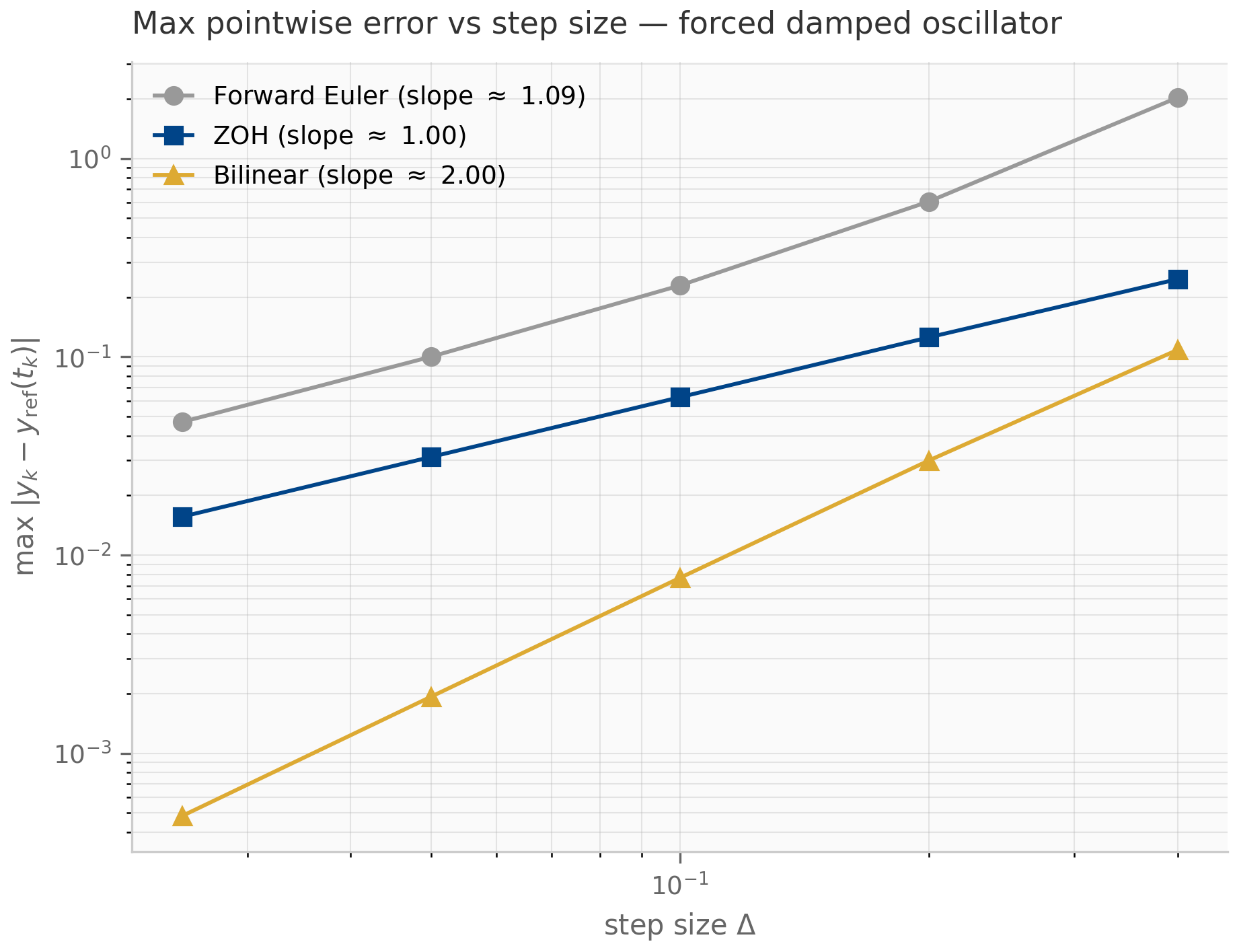
Two further properties are worth highlighting. First, for the autonomous ODE (), ZOH is exact: the recurrence matches without any error at all. This is unusual — most discretizations have nonzero error even on autonomous systems. Second, for forced systems with , ZOH is first-order accurate: the per-step error in the forcing integral is (because the integrand is over an interval of length ), and after steps the cumulative error is . The empirical convergence rate plotted in the companion log-log error figure confirms slope .
4.4 The bilinear (Tustin) transform
The second scheme drops the piecewise-constant assumption and instead approximates the integral on by the trapezoidal rule: . Applied to the inhomogeneous ODE this gives an implicit recurrence,
which one solves for :
Reading off and ,
This is the bilinear transform, also called the Tustin transform after Arnold Tustin’s 1947 paper introducing it in control theory Tustin (1947) . The original S4 paper uses bilinear discretization (S4D supports either bilinear or ZOH); so do many signal-processing toolboxes.
The bilinear formula has a striking geometric interpretation. Restricted to a single eigenvalue of (commuting through the simultaneous diagonalization), the map that sends a continuous eigenvalue to its discrete image is
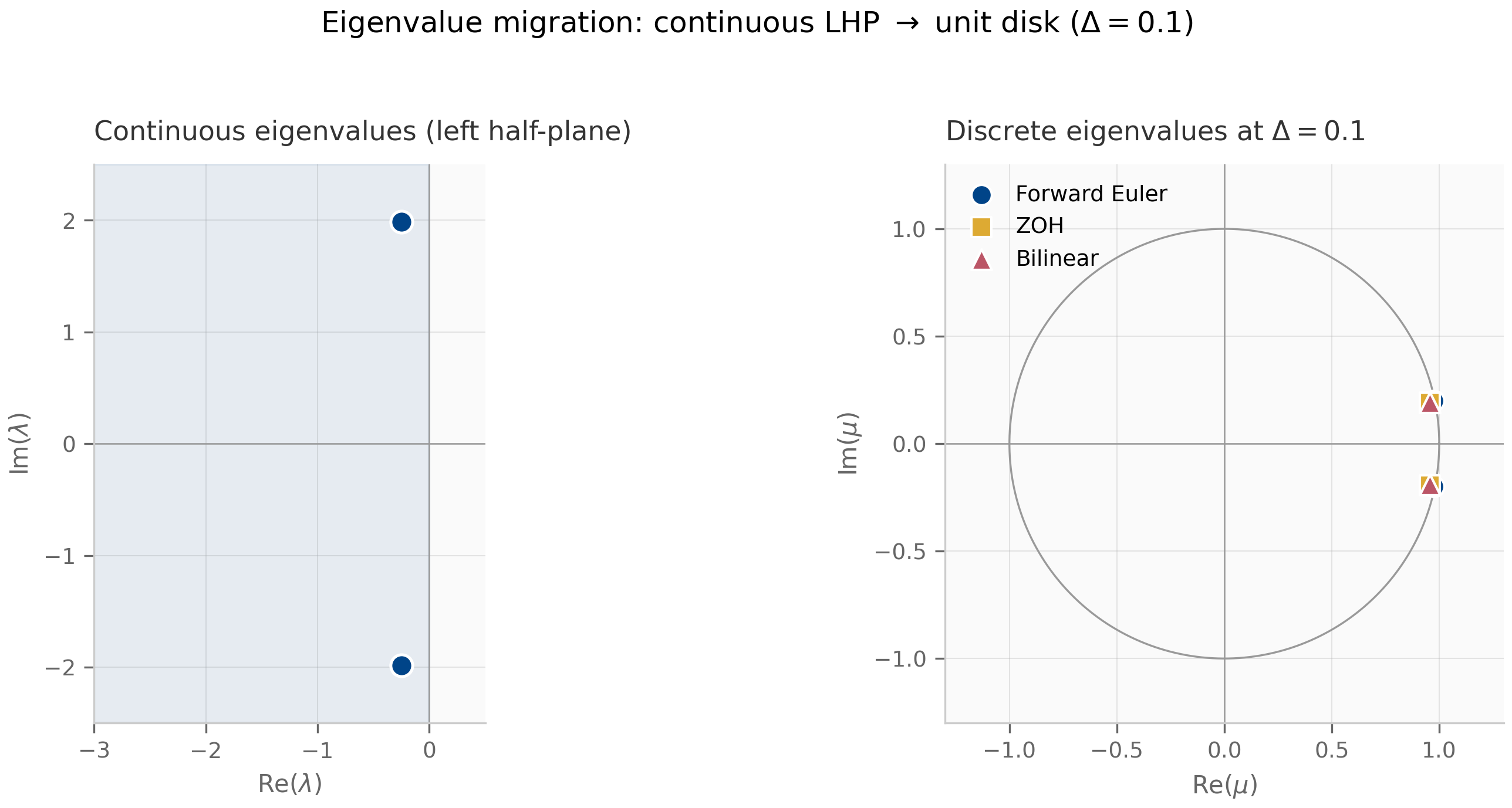
This is a Möbius transformation (a.k.a. fractional linear transformation) of the complex plane: with . Möbius transformations are conformal — angle-preserving — and they map circles-or-lines to circles-or-lines. The specific Möbius map above sends the imaginary axis exactly to the unit circle and sends the open left half-plane exactly to the open unit disk.
(Bilinear preserves Lyapunov stability.) If every eigenvalue of has and , then every eigenvalue of satisfies . Bilinear is therefore A-stable.
The proof is geometric: has , and iff (square both sides and cancel). Algebraically, , which is exactly . The full proof, with the Möbius geometry spelled out, is Exercise 4.5 in §4.9.
Bilinear is second-order accurate for smooth forcing — the trapezoidal-rule local truncation error is , giving global error . Unlike ZOH, it is not exact even on autonomous systems: the Padé approximation of agrees with the true exponential only through second order. The trade is one of structure. Both schemes send purely imaginary eigenvalues onto the unit circle: for , ZOH gives the discrete eigenvalue of modulus (ZOH is autonomous-exact, so it reproduces the oscillation outright), and the bilinear Möbius image likewise has modulus 1 — neither damps a marginally stable mode. They differ in how they wrap the imaginary axis onto the circle: ZOH’s map is -periodic, so frequencies above the Nyquist rate alias onto lower ones, whereas the bilinear map is injective on the imaginary axis — it never aliases, at the cost of warping the frequency scale (compressing large toward ). Bilinear is therefore the natural choice when a system has fast oscillatory modes you need to keep distinct; preserving oscillatory structure is the thread the symplectic methods of Chapter 6 take up in earnest.
4.5 Exponential-family discretizations
The third family takes a different approach: rather than approximating by a low-order Padé form (as bilinear does) or by the identity-plus-linear truncation (as forward Euler does), it computes exactly and approximates only the forcing integral. This is the philosophy of exponential integrators Hochbruck & Ostermann (2010) .
The exact one-step formula from variation of parameters (Chapter 1, §1.2) is
ZOH approximates on ; bilinear approximates the integral by the trapezoidal rule with a Padé-approximated exponential. The exponential-trapezoidal scheme keeps the exact exponential and uses a linear interpolation of the input: . Substituting and evaluating the resulting two integrals gives
where and are the first two -functions of the exponential family:
Both are entire functions (the apparent singularities at are removable: , ). Applied to the matrix , they produce matrix-valued objects that can be computed via the same augmented-matrix-exponential trick as ZOH.
Reading off the discrete matrices in the form :
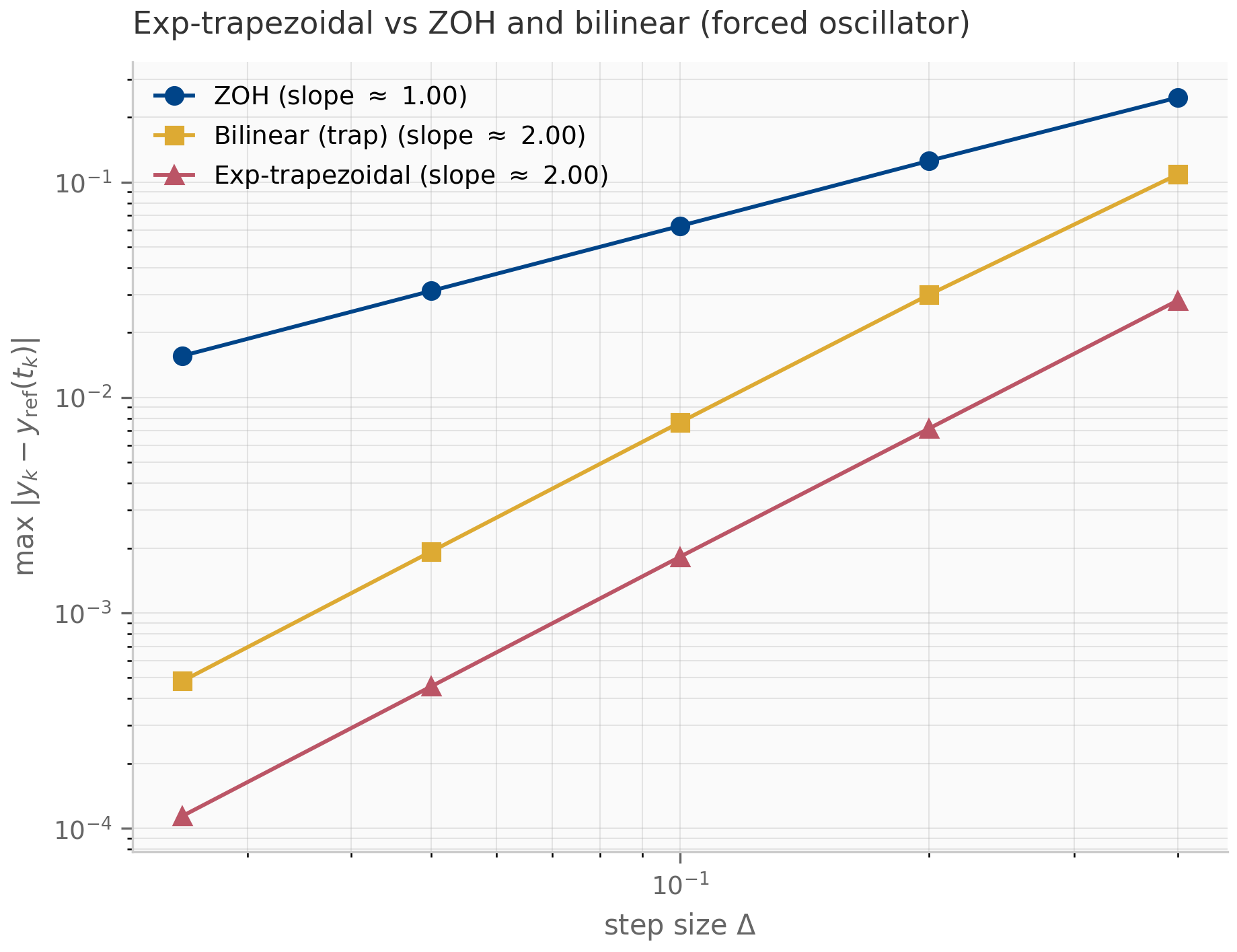
Notice that is the same as ZOH, so exp-trapezoidal preserves stability identically to ZOH: A-stable, exact for autonomous systems, eigenvalues in the unit disk for any . The improvement is in the order of accuracy: by interpolating linearly rather than holding it constant, exp-trapezoidal becomes second-order accurate (provided is — the linear-interpolation error is governed by ).
Exp-trapezoidal is the discretization of choice when the continuous dynamics are stiff — when has eigenvalues with very different magnitudes, so the linear part is the hard part of the problem. By treating exactly the scheme sidesteps the step-size restriction that explicit methods inherit from the stiff eigenvalues, and the matrix exponential is computed once per layer in practice. Chapter 10 returns to this story for Mamba-3, which adopts a scheme from this exponential-trapezoidal family precisely because the input-dependent in selective SSMs produces stiff dynamics that ZOH and bilinear handle poorly.
A subtle implementation point: is not numerically equal to when this formula is computed naively, because catastrophic cancellation in the numerator destroys precision for small . The standard remedy is to compute all -functions simultaneously from one augmented matrix exponential Al-Mohy & Higham (2011)
, again using the trick that produced for ZOH. Both companions (exp_trapezoidal.py in JAX and discretization_atlas.jl in Julia) implement the augmented form.
4.6 Order of accuracy and the discretization hierarchy
The three schemes are summarized in the table below. “Autonomous-exact” means the scheme produces zero error for the homogeneous problem (). “A-stable” means for every on every stable LTI test problem.
| Scheme | | Order | Autonomous-exact | A-stable | |---|---|---|---|---| | Forward Euler | | 1 | No | No | | ZOH | | 1 | Yes | Yes | | Bilinear (Tustin) | | 2 | No | Yes | | Exp-trapezoidal | | 2 | Yes | Yes |
The empirical order can be read directly off a log-log plot of error against step size: a -th-order scheme has error , so on a log-log plot the data lie on a line of slope . The Julia companion discretization_atlas.jl runs this sweep against a high-accuracy Tsit5 reference solution from DifferentialEquations.jl; the JAX companion discretization_comparison.py performs the same sweep using scipy.integrate.solve_ivp (Radau) as the reference.
The hierarchy is not strict: ZOH’s autonomous-exactness can outweigh its first-order accuracy when the forcing is mild relative to the homogeneous decay. Bilinear’s exact imaginary-axis preservation can outweigh its non-exactness on autonomous problems when the system has long-lived oscillations. Exp-trapezoidal combines the best of both — exact on autonomous, second-order on forced — at the cost of computing more -functions per step. The trade-offs are recurring themes throughout the SSM literature: the original S4 discretized with bilinear Gu et al. (2022) ; S4D supports either rule and finds the choice empirically negligible Gu et al. (2022) ; S5 and the Mamba line settled on ZOH for its simplicity and exactness on the (autonomous) drift; Mamba-3 switches to exp-trapezoidal once the input-dependence makes the dynamics stiff enough that the second-order error compounding matters.
4.7 What’s next
This chapter introduced three schemes and proved each preserves Lyapunov stability. Chapter 5 zooms in on the stability region of each scheme — the set of values for which — and develops the Butcher-tableau machinery for systematically constructing higher-order Runge–Kutta methods. Chapter 6 then asks what to do when even A-stability is not enough — when the system is stiff or Hamiltonian and you need L-stable implicit methods, or symplectic methods that preserve geometric invariants. The exp-trapezoidal scheme of §4.5 turns out to be a member of a much larger family of exponential integrators, all of which deserve a place in your numerical-analysis toolkit.
Forward-looking SSM connections: ZOH is this book’s default in Chapters 7–9, and natively the choice of S5 and Mamba-1/2; the original S4 and S4D papers used bilinear, with the S4D ablations finding the two interchangeable. Mamba-3 uses a scheme from this exponential-trapezoidal family, treated in Chapter 10 — §10.2 derives the specific trapezoidal-quadrature variant it adopts, a second-order cousin of the -interpolant form above.
4.8 Exercises
Six problems mixing computation and theory. Short/numerical (4.1–4.3) have inline collapsible solutions; long/proof exercises (4.4–4.6) have full worked solutions in §4.9.
Exercise 4.1 (computation)
Compute for ZOH on the 1-D test problem , , . Then verify by hand that .
Solution
. The discrete eigenvalue is , strictly inside the unit disk. The continuous decay rate is per unit time; the discrete decay factor per step is , so after 10 steps (one continuous-time unit) the state is reduced by a factor — matching the continuous decay exactly. ZOH is autonomous-exact.
Exercise 4.2 (computation)
Compute for the bilinear transform on the same 1-D problem (, ). Compare against — which is smaller, and why?
Solution
. ZOH gives . The bilinear value is slightly smaller, meaning bilinear overdamps slightly relative to the true exponential. This is the second-order Padé approximation underestimating : bilinear’s is the -Padé approximant of (the §4.4 margin note), which matches through but carries at third order against the exact , so the leading gap is at . For small the gap is ; here the net difference (after the higher-order terms) is about .
Exercise 4.3 (computation + code)
Run companions/ch04/jax/discretization_comparison.py and verify empirically that ZOH has slope on the log-log error-vs- plot, bilinear and exp-trapezoidal have slope . What happens to the ZOH slope if you set the forcing (autonomous case)?
Solution
The companion’s error_sweep function prints slopes near 1.00, 2.00, 2.00. Setting in the autonomous case makes ZOH exact — the error drops to roundoff ( in float64) and the slope is meaningless. This is consistent with the autonomous-exactness property of §4.3: ZOH’s only error source for forced systems is the piecewise-constant approximation of .
Exercise 4.4 (theory) — solution in §4.9
Prove the augmented matrix exponential trick used in §4.3: that
for invertible , by computing the series term-by-term.
Exercise 4.5 (theory) — solution in §4.9
Prove that the Möbius transformation sends the open left half-plane bijectively to the open unit disk , and sends the imaginary axis bijectively to the unit circle (minus the point ).
Exercise 4.6 (theory) — solution in §4.9
Derive the exponential-trapezoidal scheme of §4.5 from the variation-of-parameters formula by substituting the linear interpolation into the forcing integral and evaluating term-by-term using the -function identities.
4.9 Full solutions to theory exercises
Solution to Exercise 4.4
The matrix satisfies, for ,
This is verified by induction: matches by construction, and as required. Now sum the matrix-exponential series:
where , using invertibility of to extract the leading . Plugging back gives the claimed result. ∎
This is exactly the identity used to compute and jointly from one expm call in §4.3: take and .
Solution to Exercise 4.5
Let . Imaginary axis to unit circle: for with ,
so lies on the unit circle. The map traces the unit circle once as ranges over , missing only the limit point .
Left half-plane to unit disk: write with . Then
Since , (both for where the signs match the absolute values, and for where they reverse). The -terms are identical in numerator and denominator. Therefore the numerator is strictly less than the denominator, so .
Bijectivity: Möbius transformations with are bijections of the Riemann sphere to itself. Restriction to the half-plane gives a bijection to the disk. The inverse is , which can be verified by direct computation. ∎
This Möbius geometry is the algebraic content of A-stability for bilinear: a scheme is A-stable iff its eigenvalue map sends the open left half-plane into the closed unit disk. Bilinear achieves this bijectively; ZOH does so as well but non-bijectively (it folds an infinite strip of width onto the unit disk, aliasing high-frequency continuous modes onto low-frequency discrete ones).
Solution to Exercise 4.6
Start from variation of parameters on :
Substitute the linear interpolant for :
with and . Change variables in :
where in the last step we substituted the definition applied with argument . For , change variables again , so and :
The remaining -weighted integral evaluates via integration by parts to , using the identity. Carefully tracking the algebra gives as claimed. Combining,
The local truncation error is for inputs (the linear-interpolation error is — governed by — over an interval of length , and the integral picks up an additional factor). Global error is therefore — second-order, as advertised.
4.10 Companion code
Two JAX companions, two PyTorch companions, and one Julia companion for Chapter 4:
JAX (companions/ch04/jax/):
discretization_comparison.py— implements ZOH, bilinear, and forward Euler in JAX; runs the error-vs-step-size sweep on a forced damped oscillator; emitseigenvalue_migration.pngandorder_convergence.png.exp_trapezoidal.py— implements the exp-trapezoidal scheme via the augmented matrix exponential; verifies second-order convergence against the same forced oscillator; emitsexp_trap_convergence.png.
Julia (companions/ch04/julia/):
discretization_atlas.jl— ports the post_transformers Week-9 reference implementation to ssm-foundations; usesDifferentialEquations.jlTsit5as the ground-truth reference solver and reports the empirical slope per scheme.Project.toml/Manifest.toml— companion-local Julia environment pinningDifferentialEquationsandLinearAlgebra.
PyTorch (companions/ch04/torch/):
discretization_comparison.py— the forward-Euler / ZOH / bilinear discretizers and the error-vs-step sweep (compute-only; the JAX companion produces the figures).exp_trapezoidal.py— the exp-trapezoidal scheme via the augmented matrix exponential, with ZOH and bilinear baselines.tests/— cross-framework parity: the torch discretizers and trajectories equal their JAX counterparts to within (float64).
To run from the repo root:
# JAX (uses post_transformers .venv with scipy, numpy, matplotlib, jax pre-installed)
PYTHONPATH=. python companions/ch04/jax/discretization_comparison.py
PYTHONPATH=. python companions/ch04/jax/exp_trapezoidal.py
# PyTorch (needs the .venv [torch] extra; parity only, no figures)
PYTHONPATH=. python companions/ch04/torch/discretization_comparison.py
PYTHONPATH=. python companions/ch04/torch/exp_trapezoidal.py
# Julia (first run will precompile DifferentialEquations.jl; ~2–5 minutes)
julia --project=companions/ch04/julia companions/ch04/julia/discretization_atlas.jlAll figures emit to public/figures/ch04/.