Linear algebra for sequence models: structured matrices and conditioning
Eigenvalue and SVD decompositions, condition number, the four structured-matrix families (Toeplitz, Vandermonde, Cauchy, semiseparable), low-rank updates, and a Krylov-subspace primer — the linear-algebra vocabulary later chapters assume.
On this page
- 3.1 Eigenvalue decomposition and Jordan normal form
- 3.2 Singular value decomposition
- 3.3 Condition number
- 3.4 Structured matrix families
- Toeplitz matrices
- Vandermonde matrices
- Cauchy matrices
- Semiseparable matrices
- 3.5 Low-rank corrections and rank-1 updates
- 3.6 Krylov subspaces: a primer
- 3.7 What’s next
- 3.8 Exercises
- Exercise 3.1 (computation)
- Exercise 3.2 (computation)
- Exercise 3.3 (computation)
- Exercise 3.4 (computation)
- Exercise 3.5 (theory) — solution in §3.9
- Exercise 3.6 (theory) — solution in §3.9
- 3.9 Full solutions to theory exercises
- Solution to Exercise 3.5
- Solution to Exercise 3.6
- 3.10 Companion code
Linear algebra for sequence models: structured matrices and conditioning
3.1 Eigenvalue decomposition and Jordan normal form
Chapter 1’s matrix exponential built directly on the spectral structure of . The fundamental theorem is:
For every matrix , there exist matrices (invertible) and (block-diagonal with Jordan blocks on the diagonal) such that
is the Jordan normal form of ; the diagonal entries of are the eigenvalues of (counted with algebraic multiplicity); for each eigenvalue, the number of Jordan blocks equals its geometric multiplicity and the sum of their sizes equals its algebraic multiplicity. If every eigenvalue has equal algebraic and geometric multiplicity, all Jordan blocks have size 1 and is diagonal — is diagonalizable.
A Jordan block of size for eigenvalue looks like
i.e. eigenvalue on the diagonal, ones on the superdiagonal, zeros elsewhere. The matrix exponential of a Jordan block is
which is the source of the polynomial-in- factors mentioned in Chapter 1, §1.2 — they appear exactly when there are Jordan blocks of size .
For SSM analysis, the diagonalizable case dominates. Almost every arising from random initialization or from training is diagonalizable; the non-diagonalizable case is a measure-zero, codimension-one subset of parameter space and shows up only at carefully-tuned boundaries. But structured or learned — HiPPO-LegS, S4’s DPLR parametrization, the critically-damped regime of §1.3 — can carry Jordan structure by design, and Chapter 2’s Lyapunov theorem explicitly handles the defective case.
3.2 Singular value decomposition
The eigenvalue decomposition requires to be square; for general (rectangular or possibly non-diagonalizable) matrices, the right tool is the singular value decomposition.
For every matrix , there exist orthogonal matrices , , and a diagonal-with-zeros matrix with non-negative entries on the diagonal, such that
The are the singular values of ; they are uniquely determined. The number of nonzero equals .
The SVD has three properties that make it the workhorse of numerical linear algebra:
- It always exists. Unlike the eigenvalue decomposition, no diagonalizability or even squareness assumption is needed.
- The singular values give the Frobenius and operator norms. (operator norm, equal to the largest singular value); .
- It reveals low-rank structure cleanly. Truncating the SVD at rank — keeping only the top singular values and corresponding columns of — gives the best rank- approximation to in both Frobenius and operator norms (the Eckart–Young theorem).
For square , the singular values are related to but distinct from the eigenvalues. The relationship (using descending order on both sides) lets you compute singular values via an eigenvalue problem on the Gram matrix — though in practice the QR-iteration-based SVD algorithm (LAPACK’s gesdd) is more numerically stable.
The SVD shows up explicitly in:
- Chapter 2’s Lyapunov-exponent computation (singular values of the propagated frame matrix).
- Chapter 8’s HiPPO matrix analysis (the conditioning of the projection operator is given by its SVD).
- Chapter 12’s delta-rule lineage (DeltaNet’s state update is a rank-1 SVD correction).
For a textbook treatment of the SVD’s properties and algorithms, Trefethen–Bau Trefethen & Bau (1997) Chapters 4–5 are the standard reference. Golub–Van Loan Golub & Van Loan (2013) covers the algorithmic details exhaustively.
3.3 Condition number
The condition number of a matrix (with respect to the operator norm) is
the ratio of the largest to smallest singular value (when is invertible; otherwise ). The condition number measures how much amplifies relative input perturbations into relative output perturbations: if and has relative error , then the relative error in the computed solution can be as large as .
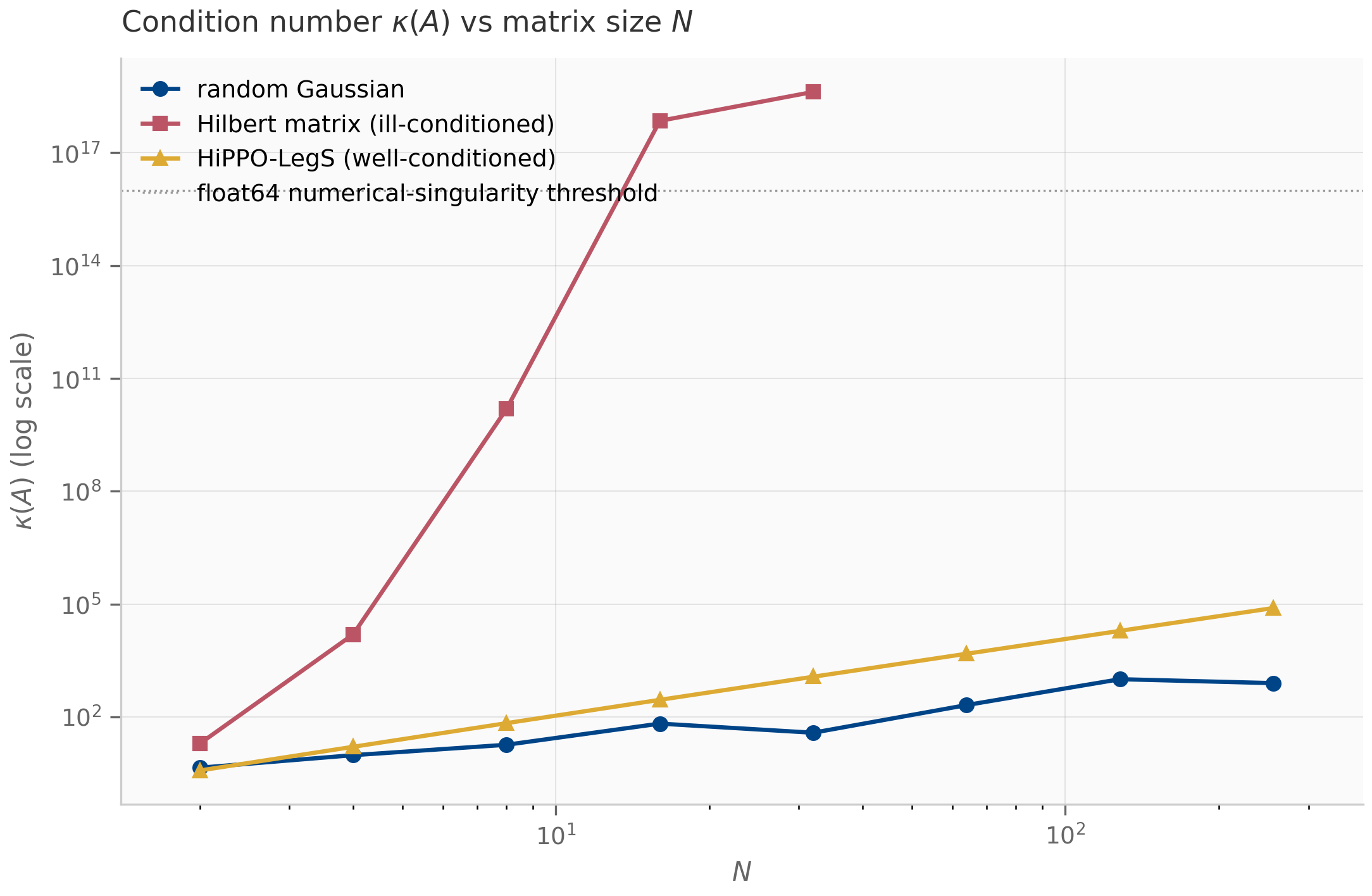
The qualitative scale: is the orthogonal case (no amplification); means losing roughly decimal digits of precision when solving a linear system. Double-precision floating point has about 16 decimal digits; matrices with are numerically singular.
For SSMs, condition number matters in three places:
- HiPPO matrix construction. The HiPPO-LegS matrix’s condition number grows polynomially with (empirically ) — far below the exponential blow-up of a generic ill-conditioned family like the Hilbert matrix, though above a random Gaussian’s . HiPPO-LegS is the standard SSM initialization for its optimal-polynomial-projection memory Gu et al. (2020) , not for being the best-conditioned matrix; its merely-polynomial growth is what keeps large- initialization numerically tractable. A subtler point: HiPPO-LegS is highly non-normal, so its eigenvector matrix is exponentially ill-conditioned in and naive diagonalization is numerically fragile Yu et al. (2023) .
- S4 kernel computation. S4’s Vandermonde-Cauchy kernel construction requires inverting a matrix with structured but potentially ill-conditioned columns. The paper carefully handles the conditioning; naive implementations don’t.
- Mamba-3’s complex-state design. Chapter 10 discusses how Mamba-3 deliberately places eigenvalues in a region of the complex plane where the discrete-time map remains well-conditioned across the integration step Lahoti et al. (2026) .
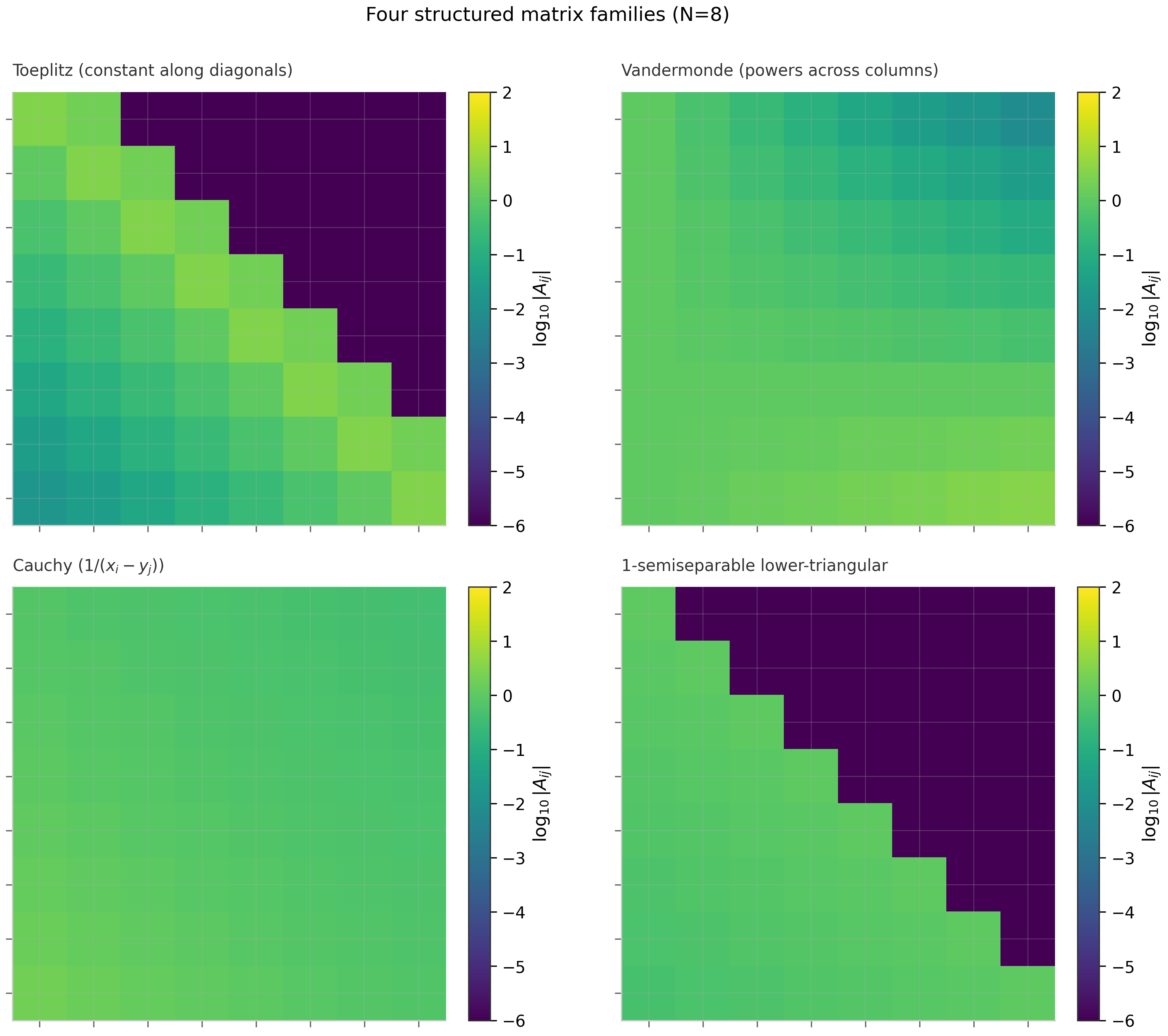
3.4 Structured matrix families
Four classes of structured matrices appear throughout the SSM literature. Each is parameterized by numbers rather than the a general matrix needs, and each admits fast matrix-vector products via specialized algorithms.
Toeplitz matrices
A Toeplitz matrix is constant along each diagonal:
Parameterized by values . Toeplitz matrices are the matrix form of convolutions: if is Toeplitz with first column and first row (lower-triangular Toeplitz), then is the discrete convolution of the kernel with . The FFT-based convolution algorithm computes in time.
The LTI SSM convolutional view (Chapter 8) is exactly this: the operator that maps the input sequence to the output sequence via is a Toeplitz matrix at the discretization level, with first column equal to the discretized impulse response .
Vandermonde matrices
A Vandermonde matrix has the form
parameterized by values . The defining property is that is a polynomial in evaluated at the node . So Vandermonde matrices implement polynomial evaluation at points as a linear map.
Vandermonde matrices are notoriously ill-conditioned for nodes on the real line (condition number can grow exponentially), but well-behaved for nodes on the unit circle — which is why the FFT (Vandermonde with being roots of unity) is numerically stable.
The S4 kernel computation uses Vandermonde structure: evaluating over is exactly the Vandermonde-style polynomial evaluation. The S4 paper Gu et al. (2022) uses Cauchy-matrix tricks (next subsection) to make this evaluation stable.
Cauchy matrices
A Cauchy matrix has entries
parameterized by values with the empty (to avoid zero denominators). Cauchy matrices are dense — every entry depends on both indices — but the very structured dependence enables fast algorithms: a Cauchy matrix-vector product can be computed in time using the fast multipole method.
Cauchy matrices appear in two places in the SSM literature: the S4 paper uses them as a numerically stable replacement for direct Vandermonde-style kernel evaluation, and the diagonal-plus-low-rank parametrization of in S4 has a Cauchy-matrix interpretation when viewed through the partial-fraction decomposition of its transfer function.
Semiseparable matrices
A rank- semiseparable matrix has the property that every submatrix lying strictly above the main diagonal (and every submatrix lying strictly below) has rank at most . Equivalently, the upper and lower triangular parts each have rank- structure.
The 1-semiseparable case — every off-diagonal block has rank at most 1 — is the structure exploited by Mamba-2’s SSD framework Dao & Gu (2024) . The 1-semiseparable lower-triangular matrix corresponding to a scalar-times-identity SSM is, explicitly,
where is the (scalar) recurrence coefficient at step . The entry for is the product . The SSD insight is that this matrix-vector product can be computed two ways: as a scan (the SSM view, time) or as a structured matrix multiply (the attention view, time but matmul-friendly on GPUs).
When is moderate (say ) and the GPU favors matmul over scan, the matrix view wins; when is huge, the scan view wins. Mamba-2’s chunked algorithm interpolates: matrix-multiplies within chunks of size , scans across chunks. This is the structural reason Mamba-2 is faster than Mamba-1 on long sequences without sacrificing parallelism.
3.5 Low-rank corrections and rank-1 updates
A recurring pattern: take a structured matrix (diagonal, banded, or semiseparable) and add a small low-rank correction where with . The resulting matrix retains nearly the storage and matvec efficiency of , and admits a closed-form inverse via the Sherman–Morrison–Woodbury identity:
The cost is dominated by inverting the matrix , not the outer matrix.
This pattern appears in S4 explicitly: the HiPPO-LegS matrix isn’t diagonal, but it is “diagonal plus low-rank” — specifically, normal plus low-rank, which is what makes the kernel computation tractable. The S4 paper’s main algorithmic contribution is a specialized Sherman–Morrison-style trick for this exact decomposition.
The pattern recurs even more visibly in DeltaNet (Chapter 12), where the state update is
The middle factor is a rank-1 correction (an identity minus a rank-1 outer product), and the whole expression is one explicit (forward-Euler) step of an online gradient-descent update on the per-token association loss — the DeltaNet view Yang et al. (2024) developed in Chapter 12. Longhorn Liu et al. (2024) is the implicit (backward-Euler) cousin, reaching the same online-ODE picture by solving at the endpoint.
The key takeaway: structured + low-rank corrections give you efficient matrix-vector products without giving up expressiveness. This is the design pattern unifying S4, DeltaNet, GLA, and the Mamba-2 SSD framework — each is a different choice of base structure and correction pattern.
3.6 Krylov subspaces: a primer
The Krylov subspace of order generated by a matrix and a vector is
Krylov subspaces are the workhorse of iterative methods for large sparse linear systems: GMRES, conjugate gradient, Arnoldi iteration, Lanczos. All of them construct an orthonormal basis for and solve a small () projected problem instead of the original one.
For SSMs, the Krylov picture is conceptual rather than algorithmic. The point is that contains all the information the recurrence can extract from the initial condition in steps. If the system has eigenvalues that are decoupled from the initial direction (the so-called “unreachable subspace”), the recurrence cannot recover them, and the effective dimension of the SSM is . This is one rigorous reading of the Mamba copying-limitation results — the recurrence’s expressive ceiling is set by the Krylov dimension of relative to the input.
A full treatment of Krylov methods would fill its own chapter; the curriculum revisits the picture in Chapter 8 (where the S4 kernel can be viewed as a structured Krylov-projection problem) and in Chapter 16’s empirical-methodology discussion of why some architectures can copy strings exponentially longer than others.
For a textbook coverage of Krylov-subspace methods, Trefethen–Bau Trefethen & Bau (1997) Chapters 32–40 give the full algorithmic treatment.
3.7 What’s next
You now have the linear-algebra vocabulary the rest of the book assumes. Chapter 4 picks up the discretization thread (started in Chapter 2, §2.4) and develops it systematically: order conditions, accuracy classes, the Butcher tableau, the bilinear and ZOH derivations in detail. Chapter 7 introduces the HiPPO theory that connects orthogonal-basis approximation theory to the matrix structure of S4. Chapter 8 then shows how all four structured-matrix families combine in the S4 / S4D / S5 family.
If you’re impatient, Chapter 9’s Mamba-1/2 presentation is the payoff for the SSD discussion of §3.4 — the selective scan’s matmul-friendly chunkwise algorithm is exactly the 1-semiseparable matrix product algorithm.
3.8 Exercises
Six problems. Inline solutions for the shorter ones; full proofs for the theory exercises in §3.9.
Exercise 3.1 (computation)
Compute the Jordan normal form of .
Solution
The matrix is already in Jordan form: a single Jordan block with eigenvalue . There is one eigenvalue (algebraic multiplicity 2) but only one linearly independent eigenvector (geometric multiplicity 1), giving a defective . The transformation matrix is the identity ( directly).
Exercise 3.2 (computation)
Compute the singular values of and its operator norm.
Solution
The matrix is already in SVD form (with and ). Singular values are , . Operator norm: . (Note that swapping the diagonal entries doesn’t change the SVD; singular values are always sorted descending.)
Exercise 3.3 (computation)
For the Vandermonde matrix with nodes , write out the matrix and compute its determinant. Compare to the closed-form Vandermonde determinant .
Solution
Direct computation: .
Closed form: . ✓
Exercise 3.4 (computation)
Verify the Sherman–Morrison identity numerically: pick a random invertible matrix , vectors , and check that matches the closed-form expression to machine precision.
Solution
import numpy as np
rng = np.random.default_rng(0)
S = rng.standard_normal((3, 3))
u = rng.standard_normal(3)
v = rng.standard_normal(3)
direct = np.linalg.inv(S + np.outer(u, v))
S_inv = np.linalg.inv(S)
factor = 1.0 + v @ S_inv @ u
sherman = S_inv - np.outer(S_inv @ u, v @ S_inv) / factor
print(np.allclose(direct, sherman)) # TrueThe factor must be non-zero (the Sherman–Morrison identity fails when it is, indicating that is singular).
Exercise 3.5 (theory) — solution in §3.9
Prove the Eckart–Young theorem: the best rank- approximation to a matrix in the Frobenius norm is obtained by truncating its SVD at rank . That is, if with singular values , then minimizes over all matrices of rank .
Exercise 3.6 (theory) — solution in §3.9
Prove that any Toeplitz matrix admits a matrix-vector product in time via the FFT. Specifically, show that any Toeplitz can be embedded in a circulant matrix, whose matvec is exactly the FFT-IFFT pair applied to the kernel and input.
3.9 Full solutions to theory exercises
Solution to Exercise 3.5
The proof uses two ingredients: (a) the SVD’s unitary invariance of the Frobenius norm, and (b) the optimality of truncated diagonal matrices.
Setup. Let be the SVD with and . For any of rank , write where also has rank (rank is invariant under invertible transformations). The Frobenius norm is invariant under orthogonal transformations:
So the problem reduces to: minimize over rank- matrices .
Diagonal reduction. Write with its own SVD where . Then
The middle trace term by the von-Neumann trace inequality (with equality when ‘s singular vectors align with ‘s — i.e. is diagonal in the same basis as ). Optimizing to maximize this term subject to rank gives for and for , i.e. .
Substituting back, the minimum value is , achieved by the truncated SVD . ∎
(The proof for the operator norm follows the same structure but uses Weyl’s interlacing inequality instead of von-Neumann’s trace inequality; see Golub–Van Loan Golub & Van Loan (2013) for the detailed argument.)
Solution to Exercise 3.6
Let be Toeplitz with entries for some kernel .
Step 1 — Circulant embedding. Define a circulant matrix with first column
The first rows and first columns of exactly reproduce (the zero in the middle of is the “buffer” that prevents wrap-around contamination).
Step 2 — Padded matvec. Given , form (zero-padded). Then : the first entries of the circulant product are exactly the Toeplitz product, because the zero-padding ensures the wrap-around portion of the convolution doesn’t contaminate the top half.
Step 3 — Circulant matvec via FFT. Every circulant matrix is diagonalized by the discrete Fourier transform: , where is the -point DFT matrix. So
where is element-wise product. Both FFTs and the IFFT take time; the element-wise product is .
Total cost. for the FFTs + for the element-wise multiply + to extract the first entries = . ∎
This is the exact algorithm used to compute LTI SSM convolutions in S4-family implementations: precompute the kernel once, then convolve with any input in time.
3.10 Companion code
Two JAX companions and one PyTorch companion for Chapter 3.
JAX (companions/ch03/jax/):
condition_number.py— plots κ(A) growth for random Gaussian, Hilbert, and HiPPO-LegS matrices as N grows; produces Figure 3.1structured_matrices.py— constructs Toeplitz / Vandermonde / Cauchy / 1-semiseparable matrices for N=8 and visualizes structural patterns; produces Figure 3.2
PyTorch (companions/ch03/torch/):
condition_number.py— the same κ(A) conditioning sweep (HiPPO-LegS / Hilbert / Gaussian) in idiomatic PyTorch (compute-and-parity only; the JAX companion produces Figure 3.1).tests/— cross-framework parity: the torch condition numbers match their JAX counterparts.
To run from the repo root:
PYTHONPATH=. python companions/ch03/jax/condition_number.py
PYTHONPATH=. python companions/ch03/jax/structured_matrices.py
PYTHONPATH=. python companions/ch03/torch/condition_number.pyFigures land in public/figures/ch03/.